Understanding and Building an Object Detection Model from Scratch in Python
وقتی یک تصویر رو میبینیم مغز ما در لحظه اشیا Object های توی اون تصویر رو شناسایی میکنه از طرفی دیگر زمان زیادی میبره برای آموزش برای ماشین تا این اشیا (Object) ها رو تشخیص بده. اما اخیرا پیش هایی در سخت افزار و یادگیری عمیق اتفاق افتاده که باعث شده بینایی ماشین computer vision آسون تر و بیشتر شهودی بشه.
این یک مقاله ترجمه شده با همین عنوان است و سعی کردم تا حد امکان متن و محتوای اصلی رو دست نخورده و قابل فهم منتقل کنم.
در اینجا منظور از ساخت مدل استفاده از مدل از پیش آموزش داده شده است بیشتر تا ساخت از صفر مدل
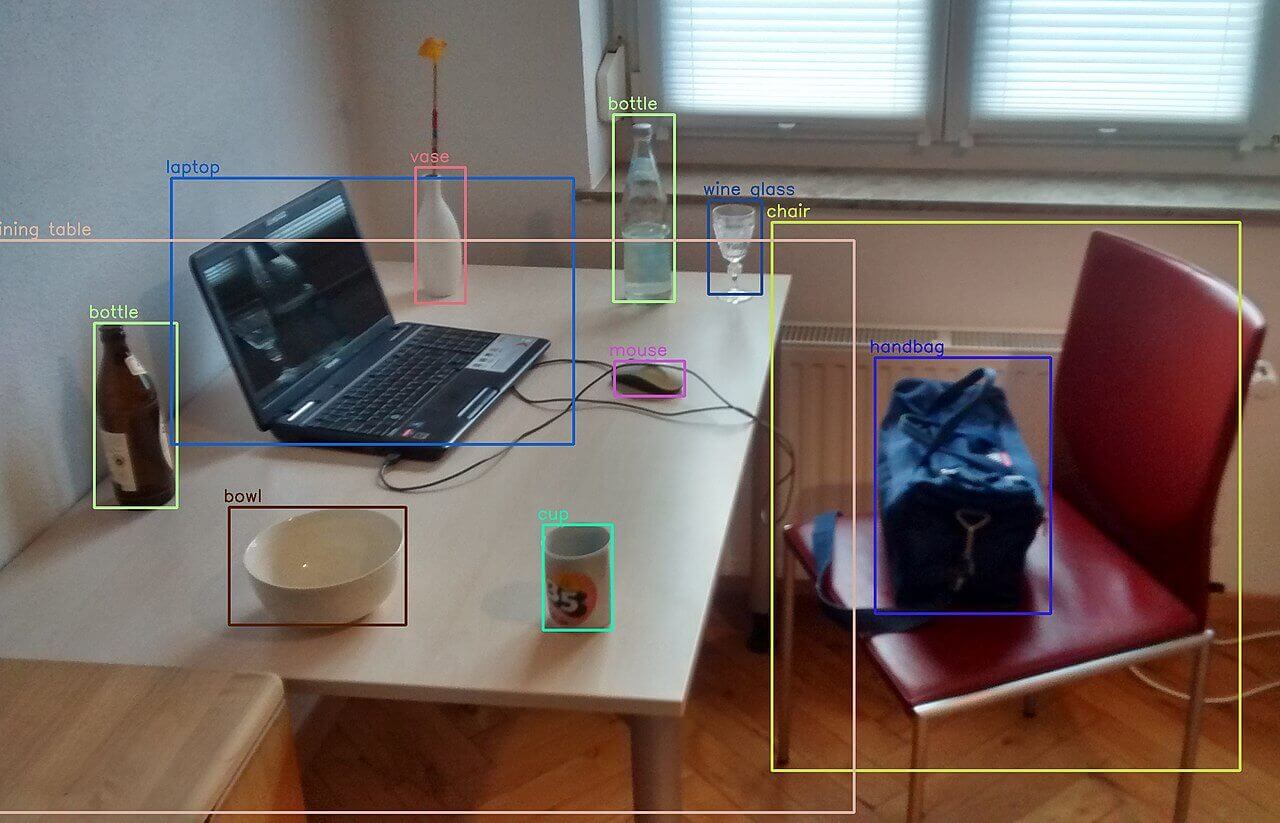
تصویر زیر رو به عنوان نمونه بررسی کنید. سیستم توانایی تشخیص اشیای مختلف توی تصویر رو با دقت باور نکردنی دارد!

تکنولوژی تشخیص اشیا در صنایع مختلف به سرعت مورد پذیرش واقع گرفته. به ماشین های خودران (self-driving) کمک میکند تا بین خطوط رانندگی کنند. رفتار های خشونت برانگیز رو در مکان های شلوغ پیدا کند. به تیم های ورزشی کمک میکند که آنالیز کنند و گزارش های استعداد یابی (scouting) رو بسازند. به خودروسازان کمک میکند که کیفیت قطعات رو موقع ساخت خودرو بررسی کنند و موارد دیگر. اینها بخشی از استفاده تکنولوژی تشخیص اشیاست (object detection) که میتواند انجام دهد.
توی این مقاله ما خواهیم فهمید که تشخیص اشیا چطوری و رویکرد های مختلف که میتوان برای حل مسائل در این زمینه حل کنیم. بعدش عمیق تر وارد میشم که سیستم تشخیص اشیا خودمون رو توی پایتون بسازیم. در انتهای این مقاله شما دانش کافی دارید که چالش های مختلف رو خودتون انجام بدید.
جدول محتوایی
- تشخیص اشیا(Object Detection) چیست؟
- رویکرد های مختلف مختلف که میتونیم یک مسئله تشخیص اشیا رو حل کنیم
- رویکرد اول : راه Naive ( تقسیم و حل)
- رویکرد دوم: افزایش تقسیمات
- رویکرد سوم: انجام تقسیمات ساختار یافته
- رویکرد چهارم: کارآمد تر شدن
- رویکرد پنجم: استفاده از یادگیری عمیق (Deep Learning) برای انتخاب ویژگی و ساخت صفر تا صد یک سیستم
- دست به کد شدن: نحوه ساخت یک مدل تشخیص اشیا با کمک کتابخانه ImageAI
تشخیص اشیا (Object Detection) به چه معناست؟
قبل اینکه برسیم به بخش ساخت یک مدل پیشرفته ابتدا اجازه دهید با سیستم تشخیص اشیا آشنا شویم. بیاید فرضا یک سیستم تشخیص عابر پیاده رو بسازیم برای ماشین های خودران. فرض کنید ماشین شما تصویری مشابه زیر رو گرفته. چطوری این تصویر رو توضیح میدید؟

این تصویر به ما نشان میدهد که ماشین ما نزدیک خط عابر پیاده است و تعداد انگشت شماری از مردم در حال عبور از خیابون جلوی ماشین ما هستند. از آنجا که علائم راهنمایی رانندگی به وضوح قابل مشاهده نیست سیستم های تشخیص عابر پیاده ماشین باید دقیقا مکان هایی که مردم قدم می زنند رو مشخص کنند تا از آنها دوری کنیم.
بنابراین سیستم ماشین چه کاری میتواند انجام دهد تا این اتفاق افتد؟ کاری که میتواند انجام دهد ایجاد یک جعبه محدود (bounding box به صورت ساده با یک شکل دور افراد آنها را مشخص کند) در اطراف این افراد مشخص کند و بر این اساس تصمیم بگیرد که کدام مسیر رو باید طی کند تا از هر گونه اشتباهی جلوگیری شود.

هدف ما در انجام شناسایی اشیا دوتاست ۱. اشیا و مکان هایشان رو توی تصویر رو شناسایی کنیم ۲. اشیا رو فیلتر کنیم
رویکرد های مختلف برای حل یک مسئله تشخیص اشیا
حالا میدونیم وضعیت مسئله ما چیست چه رویکرد احتمالی ( یا رویکرد چندگانه ای) میتواند این مسئله رو حل کند؟ در این بخش چند روش که میتواند برای تشخیص اشیا در تصویر استفاده شود رو نگاهی میندازیم. با ساده ترین روش شروع میکنیم و پیش میریم. اگر هر پیشنهادی دارید یا یک روش دیگه ای رو در نظر دارید توی بخش نظرات مطرح کنید.
رویکرد اول: روش ساده و ابتدایی (تقسیم و غلبه)
این ساده ترین روش است.ما میتونیم عکس رو به چهار بخش تقسیم کنیم.
حالا قدم بعدی این که هر بخش رو به یک کلاسیفایر - دسته بند - classifier بدیم. با این کار میتونیم بفهمیم که آیا در هر بخش خط عابر پیاده هست یا نه. اگر بله اون قسمت تصویر رو علامت گذاری کنیم تا چیزی شبیه این بشه:

این یک رویکرد خوب ابتدایی است ولی ما دنبال سیستم دقیق تری هستیم. نیازه که شناسایی کنه تمام اشیا (در اینجا افراد رو) به خاطر اینکه یافتن فقط بخشی از اشیای توی تصویر می تواند به نتایج فاجعه باری بیانجامد.
رویکرد دوم: افزایش تعداد تقسیمات
سیستم قبلی خیلی خوب کار میکرد چه کار دیگه ای میشه انجام داد؟ ما میتونیم با افزایش نمایی تعداد تکه ها ( هر بخش رو میدیم به یک مدل خاص) بهبود بدیم و خروجی ما اینگونه خواهد شد:

در نهایت این یک خوبی و بدی دارد. راه حل فعلی ما از روش قبلی که روش ساده ای بود به نظر میرسید بهتر است. با تعداد زیادی جعبه محدود کننده به یک چیز مشابه نزدیک میشویم. این یک مشکل است و نیازه که بیشتر ساختار دهی کنیم برای حل مسئله.
رویکرد سوم: انجام تقسیمات ساختار یافته
برای ساختن یک سیستم تشخیص شی به شیوه ساختار یافته تر میتوانیم مراحل زیر رو بریم:
قدم اول: تقسیم عکس به گرید ۱۰ در ۱۰ مشابه این:

قدم دوم: تعریف مرکزوارها Centroids برای هر بخش قدم سوم: برای هر مرکزوار سه قسمت متفاوت با ارتفاع و نسبت متفاوت انتخاب کنیم

قدم چهارم: همه قسمت های ساخته شده رو بدیم به یک دسته بند برای پیش بینی
خب حالا خروجی نهایی به چه شکل خواهد بود؟ قطعا ساختار یافته تر و منظم تر به تصویر زیر نگاهی بیاندازید:

اما ما میتونیم بیشتر از این بهبود بدیم. خوندن رو ادامه بدید تا رویکرد دیگری که نتایجی بهتر از این رو ایجاد میکنه ببینید.
مرکزوار یا مرکزوار هندسی یا گرانیگاه در ریاضیات و فیزیک، به نقطهای از یک شکل مسطح اطلاق میشود که میانگین مختصات تمام نقاطِ موجود در شکل است. به عبارتی، نقطهای است که یک شکل میتواند تعادل خود را برروی نوک یک سوزن، در آن مکان حفظ نماید. در مورد مثلث، این نقطه محل تلاقی سه میانه است.
رویکرد چهارم: کارآمد تر شدن
رویکرد قبلی که دیدیم در درجه ای قابل توجه ای قابل قبول بود اما میتونیم سیستم رو یکم کارآمد تر از اون بسازیم. پیشنهادی دارید چطوری؟ با توجه رویکرد سوم ما میتونیم دو چیز که مدل ها رو میتونه بهتر کنه انجام بدیم: ۱. افزایش سایز گرید: به جای سایز گرید ۱۰ میتونیم از ۲۰ استفاده کنیم:

۲**. به جای سه قسمت, قسمت های بیشتری با ارتفاع و نسبت ابعاد بیشتری بگیریم**: در اینجا می توانیم از یک بخش تصویر ۹ شکل مختلف رو در بیاریم. یعنی سه تکه مربع از ارتفاعات (طول های) مختلف و ۶ تکه مستطیل عمودی و افقی از ارتفاعات مختلف. این نسبت های مختلف به ما تیکه های مختلفی رو میده. (میدونم یکم پیچیده شده ساده ترش بگم با ترکیب اندازه های مختلف در نسبت های مختلف ما تصویر های زیادی رو داریم توی عکس مشهود است).

البته این جوانب مثبت و منفی هم داره و مطمئنا هر دو روش با ما کمک میکند که به سطح کوچکتری برسیم اما این دوباره باعث زیاد شدن تمام قطعات خواهد شد که باید از مدل دسته بندی تصاویر رد کنیم.
یکی از کارهایی که میتوانیم انجام دهیم به جای اینکه همه قسمت ها رو بگیریم و بدیم به مدل یک مدل طبقه بندی میانی ( متوسط - intermediate) استفاده کنیم که با ما بگه آیا این قسمت پس زمینه هست یا دارای یک شی است. اینطوری میزان تصاویری که به مدل دسته بندی تصاویر میدیم خیلی کمتر میشه.
یکی دیگه از بهینه سازی هایی که میتوانیم انجام بدیم کاهش پیش بینی های یک چیز است بیاید دوباره از رویکرد سوم استفاده کنیم:
همانطور که میبینید دو باکس پیشبینی عملا یک نفر رو مشخص کردند. ما میتوانیم فقط یکی از باکس ها رو انتخاب کنیم. خب برای پیش بینی ما توجه می کنیم به همه باکس هایی که «همان چیز» را در نظر میگیریم و سپس انتخاب میکنیم که کدامیک بیشترین احتمال شناسایی فرد رو داشته.
همه این روش های بهینه سازی به ما پیش بینی مناسبی را ارائه دادند تقریبا همه بخش ها رو در تصویر داریم آیا میتوانید حدس بزنید درباره چه چیزی صحبت نکردیم؟ البته که یادگیری عمیق.
رویکرد پنجم: استفاده از یادگیری عمیق (Deep Learning) برای انتخاب ویژگی و ساخت صفر تا صد یک سیستم
یادگیری عمیق پتانسیل ویژه در زمینه شناسایی اشیا داره. آیا شما میتونید پیشنهاد بدید کجا و چطوری میتونه به مسئله ما کمک کنه؟
من چندتا از متالوژی ها رو این زیر لیست کردم:
- به جای گرفتن بخش های از تصویر اصلی, میتونیم تصویر اصلی رو به یک شبکه عصبی بدیم برای کاهش ابعاد
- همچنین میتونیم با استفاده از یک شبکه عصبی بخش های انتخاب رو پیشنهاد بدیم
- ما میتوانیم یک الگوریتم یادگیری عمیق رو تقویت کنیم تا پیش بینی ها نزدیک تر به محدوده جعبه اصلی باشد. با این کار اطمینان حاصل خواهیم کرد که الگوریتم پیش بینی محدوده جعبه دقیق تر و ظریف تر عمل میکند
حالا به جای آموزش شبکه های عصبی مختلف برای یک هر بخش به صورت جداگانه ما میتونیم یک مدل شبکه عصبی عمیق رو که همه مسائل رو خودش حل میکند آموزش بدیم. مزیت انجام این کاراین است که هر بخش کوچک تر یک شبکه عصبی کمک میکنه به بهینه بودن بقیه قسمت های شبکه عصبی این در نهایت به ما کمک میکنه به آموزش بهتر کل مدل.
خروجی ما بهترین کارایی رو نسبت به تمام رویکرد های قبلی داره چیزی مشابه عکس زیر. در بخش بعدی خواهیم دید چطوری همچین چیزی رو با کمک پایتون بسازیم.

دست به کد شدن: نحوه ساخت یک مدل تشخیص اشیا با کمک کتابخانه ImageAI
حالا که میدونیم شناسایی اشیا چی هست و بهترین رویکرد برای حل این مسئله چیه. وقتشه که سیستم تشخیص اشیا خودمون رو بسازیم. ما با کمک ImageAI یک کتابخونه پایتونی که از الگوریتم های پیشرفته یادگیری ماشین در کارهای بینایی ماشین استفاده میکنه, استفاده میکنیم.
اجرا کردن یک مدل object detection برای پیش بینی خیلی سادس. نیازی به نصب های پیچیده برای شروع یا حتی گرافیک برای پیش بینی نداریم. ما فقط با استفاده از ImageIA خروجی مانند چیزی که توی رویکرد استفاده از یادگیری عمیق بدیدم رو میسازیم. پیشنهاد میکنم کدهای زیر رو دنبال کنید تا بیشینه یادگیری اتفاق افتد.
توجه داشته باشید که شما نیاز دارید قبل از اینکه مدل تشخیص اشیا رو بسازید سیستمتون رو آماده کنید. اگر که Anaconda دارید روی سیستم تون کافیه که مراحل زیر رو طی کنید.
قدم اول: ایجاد یک محیط Anaconda با پایتون ۳.۶
conda create -n retinanet python=3.6 anacondaقدم دوم: فعال سازی محیط و نصب پکیچ های مورد نیاز
source activate retinanet
conda install tensorflow numpy scipy opencv pillow matplotlib h5py kerasقدم سوم: نصب کتابخانه ImageAI
pip install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whlقدم چهارم: حالا یک مدل از قبل آموزش داده شده رو دانلود کنید. این مدل بر پایه RetinaNet است. لینک دانلود مدل RetinaNet
قدم پنجم: انتقال فایل کپی شده به پوشه فعلی
قدم ششم: دریافت عکس از این لینک و اسم عکس رو image.png ذخیره کنید قدم هفتم: ژوپیتر نوت بوک خودتون رو باز کنید (با تایپ jupyter notebook توی کامند لاین یا ترمینال) و کد زیر رو بزنید
{kind=link}
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
custom_objects = detector.CustomObjects(person=True, car=False)
detections = detector.detectCustomObjectsFromImage(input_image=os.path.join(execution_path , "image.png"), output_image_path=os.path.join(execution_path , "image_new.png"), custom_objects=custom_objects, minimum_percentage_probability=65)
for eachObject in detections:
print(eachObject\["name"\] + " : " + eachObject\["percentage_probability"\] )
print("--------------------------------")این تیکه کد برای ما نسخه تغییر یافته فایل image.png رو با اسم image_new.png میسازه که باکس های محدود کننده توی اون مشخص هست. قدم هشتم: برای چاپ عکس با کد زیر رو بزنید
from IPython.display import Image
Image("image_new.png")
تبریک میگم شما مدل تشخیص اشیا خودتون رو برای تشخیص عابرین پیاده ساختید. چقدر خوبه؟
سخن پایانی
توی این مقاله یاد گرفتیم که تشخیص اشیا (object detection) چیست. همچین دیدم چطوری با کمک کتابخانه ImageAI یک مدل پیش بینی اشیا بسازیم.
فقط با کمی تغییر کد میتواند برای حل چالش های تشخیص شی خود تغییر دهید اگر تونستید یک مشکلی با کمک این کد حل کنید خوشحال میشم در بخش نظرات با من در میون بذارید