
پانداس یکی از معروف ترین کتابخانه های پایتون برای استفاده در زمینه داده کاوی و نمایش دادهاست. با کمک کتابخانه مدین modin میتونید قابلیت پردازیش موازی رو در پانداس داشته باشید.
نکته مهم: برای استفاده از مدین نسخه ray حتما باید سیستم عامل شما لینوکس بیس باشه که با کمک داکر یا windows linux sub system میتونید ازش استفاده کنید.
چطوری سرعت پانداس را چهار برابر کنیم؟
چرا پانداس؟ وقتی حرف از داده ها در تایپ های مختلف میشود دیگه جایی برای نام پای نمیماندو حتی قدرت لیست های پایتون به این اندازه نیست. کئوری دیتابیسی دارید؟ مشکلی نیست با پانداس میتونید اجراش کنید. طبق امار های است اور فلو stack overflow میتوان فهمید که روند پانداس یکی از رو به رشد ترین کتابخانه های پایتون هست.
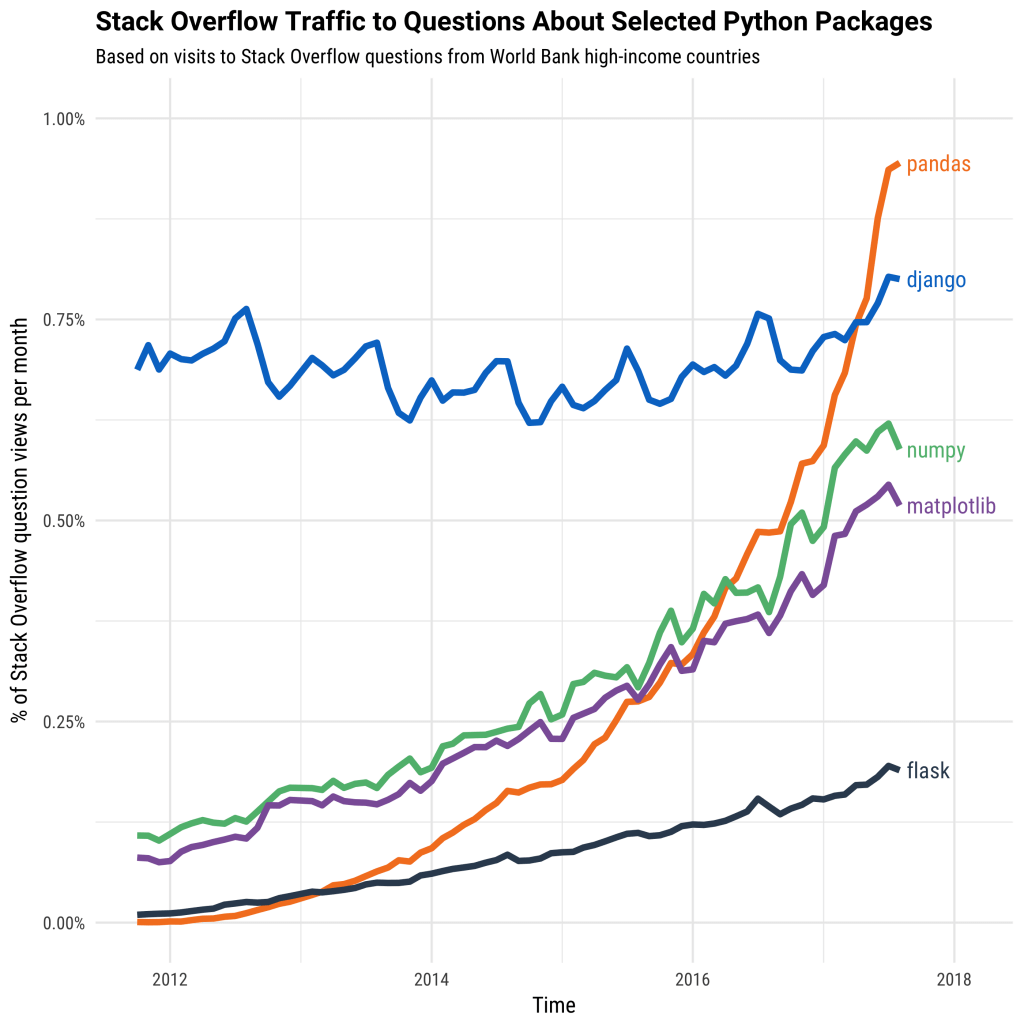
اما مشکل کجاست؟ پانداس به صورت پیش فرض از همه توان سیستم استفاده نمیکنه و مشکل ایجاد میکنه برای دیتاست های بزرگ پس چاره چیست؟ استفاده از modin حالا ببینیم چطوری میتونه به ما کمک کنه. یکم بریم در عمیق, به صورت پیش فرض پانداس روی یک هسته پردازنده اجرا میشه که برای دیتاست های کوچیک هیچ مشکلی نداره اما اگر دیتابیس بزرگ باشه؟ دیتابیس های بزرگ به خاطر تعداد زیاد محاسبات زمان بیشتری رو میطلبه برای پردازش زمانی مشکل بزرگ میشود که دیتابیس بیشتر از یک میلیون سطر و ستون داره.
برسیم به خود پردازنده ها, در حال حاضر یک لپتاپ و دکستاپ حداقل 2 هسته ( و ممکنه چهار تا ترد) داشته باشه. در سطح دکستاپ این مورد به عدد 16 هسته و 21 ترد میرسه.اگر از حالت پیش فرض پانداس استفاده کنید تنها از یک هسته استفاده میشه و عملا بقیه پردازنده بلا استفاده میمونه. البته اکثر پردازنده های مدرن حداقل 4 هسته دارند که این مساوی استفاده از ¼ منابع است. متاسفانه پانداس به صورت پیش فرض برای استفاده موازی از پردازنده بهینه نشده. مدین modin یکی از کتابخانه های تازه طراحی شده است که میتونه برای ما استفاده حداکثری پانداس از منابع رو به ارمغان بیاره. با استفاده مدین شما از تمام هسته های خودتون استفاده میکنید.
نحوه کارکرد پردازش موازی مدین پانداس
وقتی یک دیتافریم میدیم به پانداس هدف ما این هست که به سریع ترین شیوه ممکن پردازش کنیم ممکن که این پردازش ما یک میانه گرفتن باشه یا گروه بندی و حتی در مرحله پیش پردازش داده ها بخواهیم داده هایی که افزونگی دارند رو پاک کنیم. در همان نطور که در بخش قبلی گفتیم پانداس فقط از یک هسته پردازنده استفاده میکنه که به طور طببیعی یک گلوگاه ایجاد میکنه. مخصوصا وقتی که دیتافریم های ما بزرگ هستند که نبود منابع کافی برای پردازش قابل چشم پوشی نیست. به صورت تئوری پردازش موازی میتونه کمک کنه که بخش های مختلفی از داده روی هسته های مختلف قرار بگیرند. برای دیتافریم های پانداس یک ایده ساده این هست که اونها رو به بخش های مختلف تقسیم کنیم و در قالبی بدیم به هر کدوم از هسته ها و در پایان نتیجه دو پردازش رو تجمیع کنیم با هم که هزینه محاسباتی کمی داره.
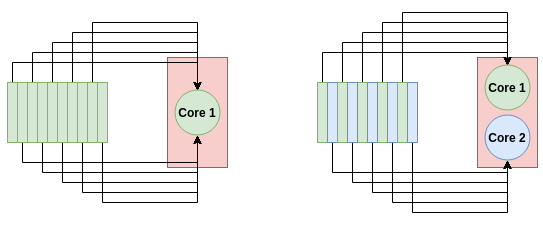
نحوه انجام فراینده ها به شیوه چند هسته ای, در سمت چپ کل 10 فراینده رو یک هسته انجام میشه در حالی که در سمت راست هر هسته 5 فرایند رو مدیریت میکنه.
این دقیقا نحوه کارکرد مدین هست. اون دیتافریم رو به بخش های مختلفی تقسیم میکنه که هر بخش میتونه روی یک هسته مختلف پردازنده قرار بگیره.مدین در واقع میاد دیتافریم رو از سطر و ستون همزمان به بخش های مختلفی تقسیم میکنه که این کار باعث میشه ما بتونیم به راحتی کاری با مقیاس بالا انجام بدیم.
حالا این کار چه فایده هایی داره؟ فرض کنید دیتاست شما تعداد زیادی ستون و تعداد کمی سطر داره اگر صرفا بر اساس تعداد سطر تقسیم بندی بشه ( کاری که معمول هست به صورت پیش فرض با چند ترد کردن) اون موقع فوایید استفاده موازی از پردازنده کم میشه و عملا ممکن به جای تاثیر مثبت سر بار بشه.
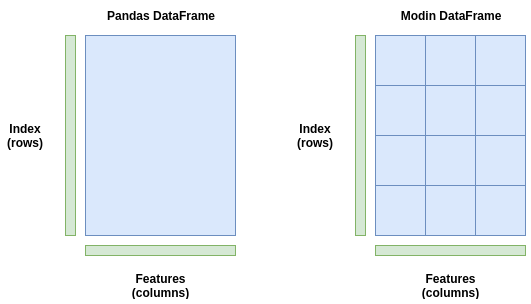
این تصویر یک مثال ساده درباره کارکرد مدین میباشد, در واقع مدیت از یک مدریت پارتیشن استفاده میکنه که این امکان رو میده تا سایز و شکل به صورت متغییر انتخاب بشه. با این کار دیگه نیازی نیست که همیشه ما سایز رو انتخاب کنیم در واقع خود مدین به صورت هوشمندانه با توجه به پردازشی که قرار هست انجام بده این مورد رو انتخاب میکنه.
وقتی حرف از کارهای زیادی توی کامپیوتر حرف میزنیم مسئله اجرای همزمان کارها میاد وسط
مدین میتونه از دو کتابخونه دسک dask و ری ray استفاده کنه. هر دوی این کتابخونه ها یک سری ای پی ای ساخته شده برای پردازش موازی هستش و شما میتونید با توجه به نیازتون یکی از اینها رو انتخاب کنید. فعلا کتابخانه ری ray ایمن تر از کتابخانه دسک است. خب دیگه بسه درباره تئوریات صحبت کردند وقتش رسیده که یکم دست به کد بشیم و بنچ مارک ها رو مقایسه کنیم.
بنچ مارک سرعت مدین modin
ساده ترین راه استفاده از مدین نصب از طریق پیپ pip هست که با کامند زیر میتونید مدین و تمام نیازمندی های مربوطش رو نصب کنید.
pip install modin[ray]دیتاست مورد استفاده ما مربوط به رقابت های CS:GO میباشد که در سایت کگل قرار دارد. حجم کلی این دیتابیس 3 گیگابایت میباشد. برای ریز تر شدن این موضوع مشخصات دیگر سیستم: cpu: i5 - 6400 up to 3 ghz ram: 24 gb 2400mhz ssd : samsung 860 evo 512gb gpu: msi 10603gb
ما در این تست ها از بخش esea_master_dmg_demos.part1.csv دیتاست استفاده میکنیم که حجم ان 1.1 گیگبایت میباشد. با این مقدار حجم شما به خوبی میتونید متوجه بشید که تفاوت های استفاده موازی از پردازنده چقدر هست. در اولین تست ما مسئله خواندن را تست میکنیم:
نمونه کد در گیت هاب: برای خواندن از تابع read_csv() استفاده میکنیم.
به طور متوسط برای بنده دو برابر سریعتر عمل کرد البته اگر حجم دیتاست بیشتر بشه عدد نزدیک به سه برابر سریع تر نزدیک میشه. این تازه شروع ماجرا هستش و در ازمایشگاه بخش ایمپورت رو هم در نظر گرفتیم که عادلانه تر باشه. البته در این میتونید نحوه کم و زیاد شدن استفاده از منابع رو ببینید. همان طور که در تصویر مشاهده میکنید موقع استفاده از پانداس به صورت متوسط از 50 درصد پردازنده و موقع استفاده از مدین به صورت 100 درصد از پردازنده استفاده میشه.
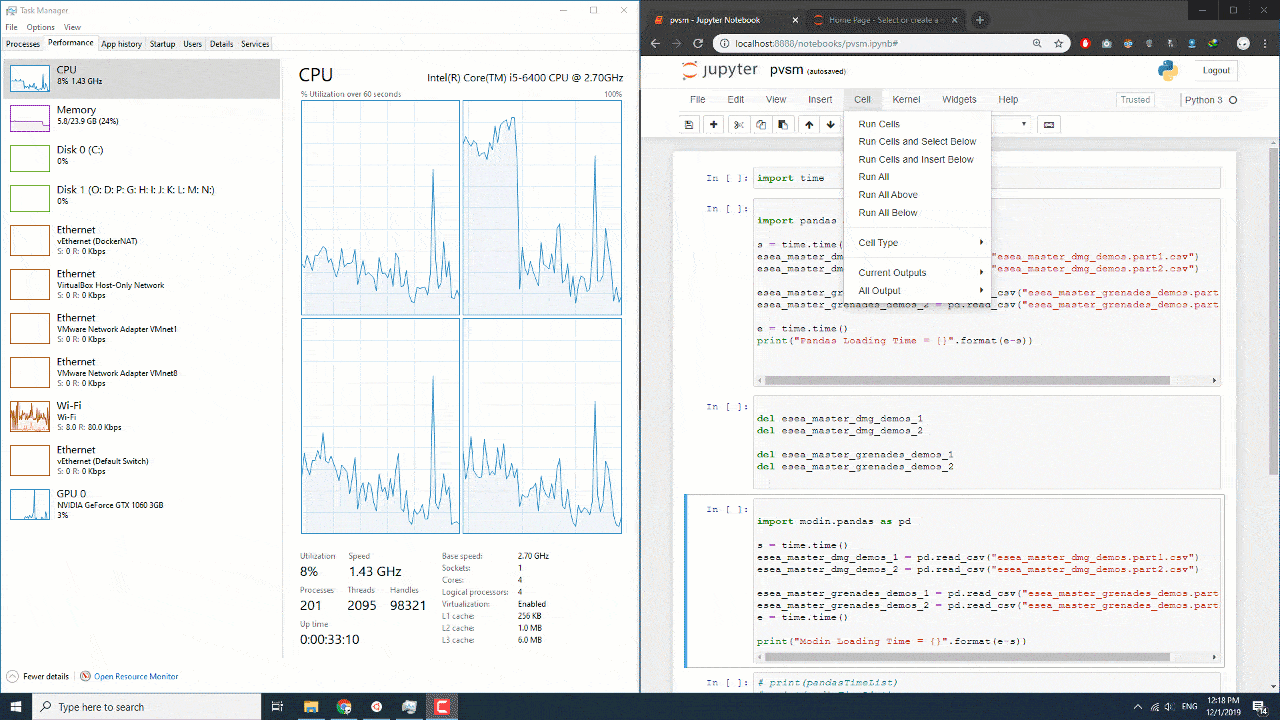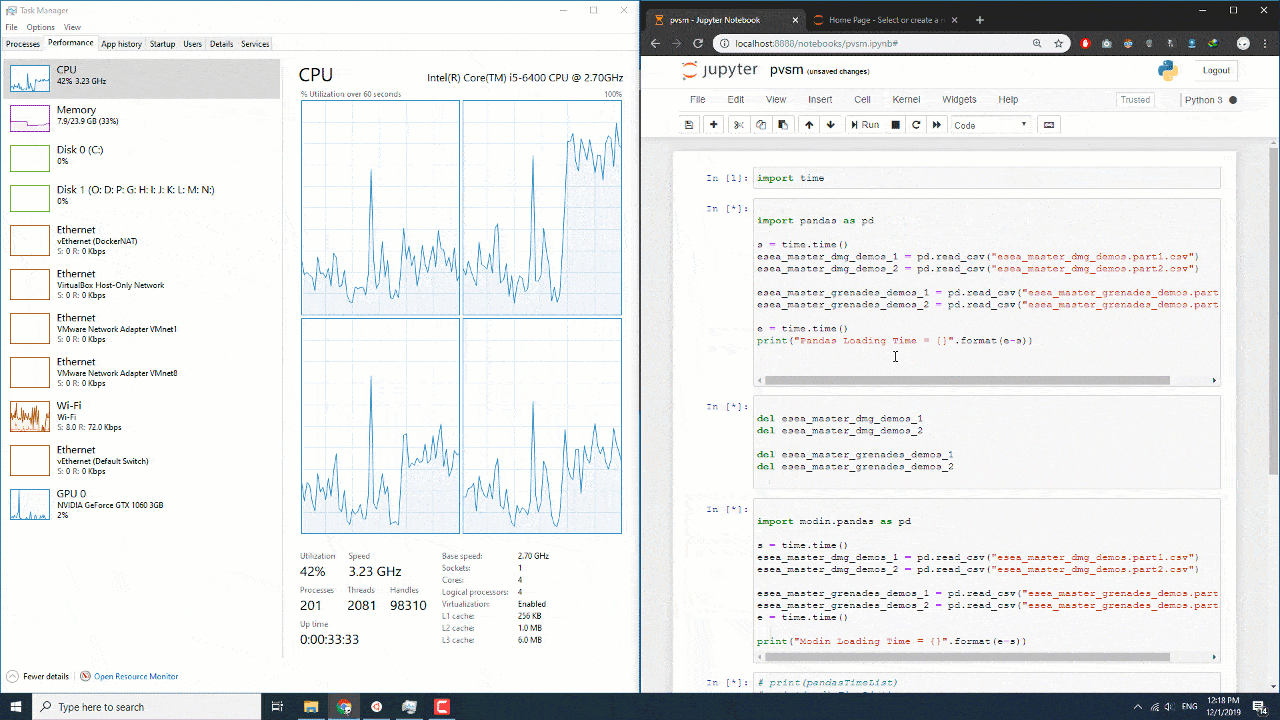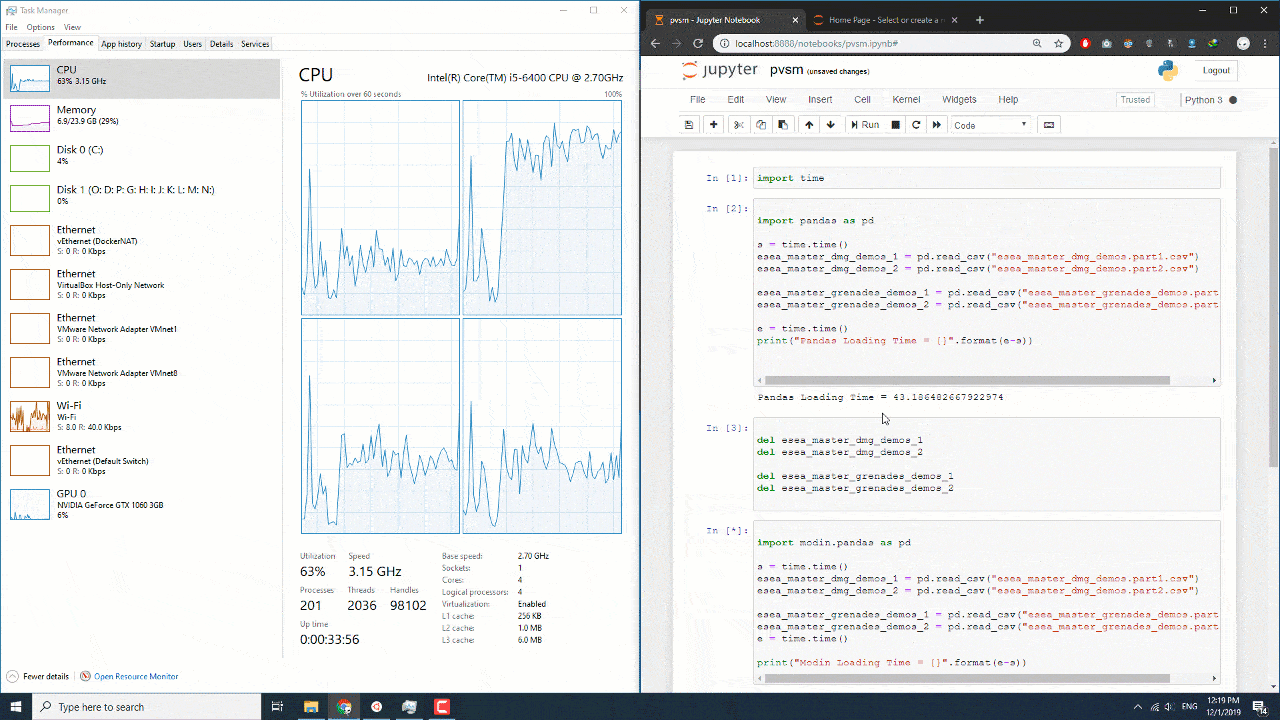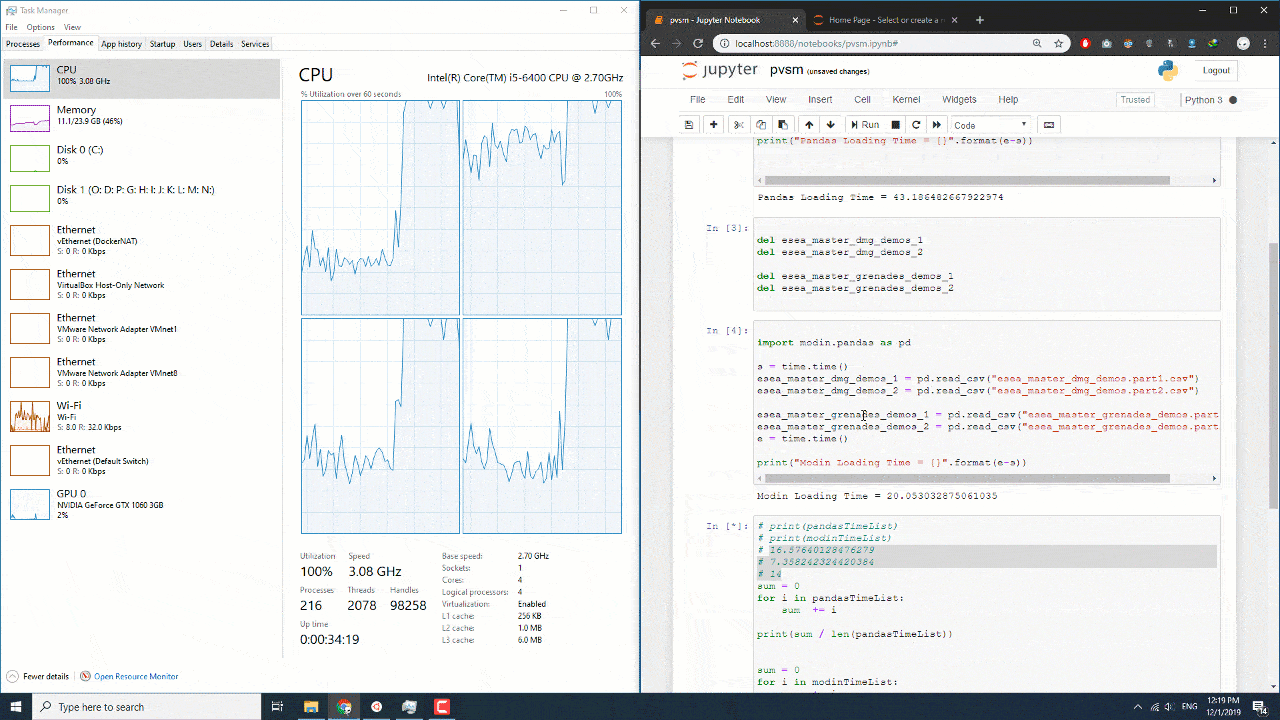
البته یک نکته ای رو در نظر بگیرید سیستم من به صورت خالص تمام منابع خودش رو دراختیار پردازش قرار نمیداده.
اجازه بدید مقداری پردازش سنگین تر رو انجام بدیم. تجمیع چندین دیتافریم یکی از کارهای معمول در پانداس هست که زمانی که ما چندین فایل CSV داریم به ما کمک میکنه که داده هامون رو یک جا کنیم. این فرایند به راحتی از طرق تابع pd.concat() قابل دسترسی است.
قبل از اجرا دوست داریم که بدونیم که مدین چطوری این فرایند سنگین رو مدیریت میکنه و اینها رو با هم تجمیع میکنه.
در کد بالا مسئله ادغام دیتافریم به صورت 5 بار با خودش هست. پانداس این عملیات رو توی 36.6 ثانیه و مدین توی 7.9 ثانیه انجام میده 4.6 برابر سریع تر. با سخت افزار بروز و پردازنده I7 8700K این فرایند تا 80 برابر سریع تر رخ میده. یکی دیگر از عملیات های مهم در پانداس پر کردن مقادیر نال یا NaN است که بتوان با یک مقدار درست انها رو مدیریت کرد در اینجا صرفا مقدایر نال رو 0 قرار میدیم.
رقم تفاوت خیره کنندس, پانداس در 4.9268 ثانیه و مدین در 0.009 انجامش داد. این مقدار تفاوت 547 برابری رو با سخت افزار من ایجاد میکنه, قطعا این فرایند برای کار با داده های زیاد و در کنار الگوریتم هایی مثل knn میتونه سرعت زیادی رو به پر کردن جای دادن های گم شده بده.
مقایسه دقیق تر:
خب همیشه مدین سریع تر هست؟ خب یکم سخت شد متاسفانه نه همیشه. بر خلاف تئوری هنوز جاهایی هستند که پانداس سریع تر عمل میکنه اما داشتن هر دو کتابخانه در کنار هم و کار کردن باهاشون میتونه کمک کنه که از حداکثر پردازش استفاده کنیم. در اینجا میتونید یک سری بنچ مارک هایی که سایت kdnuggets قرار داده رو ببیند.
نکات کاربری برای بهبود استفاده از مدین: همان طور که میدونید مدین یک کتابخونه جوان و در حال توسعه هست و اینکه هنوز تمامی توابع پانداس توی اون نیستند. البته جای نگرانی نیست در صورتی که تابعی رو صدا بزنید که وجود نداره میاد و به صورت پیش فرض از پانداس استفاده میکنه. میتونید لیست توابع مدین رو ببینید.
به علاوه به صورت پیش فرض مدین از تمامی هسته های پردازنده استفاده میکند در صورتی که میخواهید یک محدودیتی برای استفاده از پردازنده داشته باشید میتونید از تکه کد زیر استفاده کنید:
import ray
ray.init(num_cpus=4)
import modin.pandas as pdوقتی که با دیتاست های بزرگ کار میکنید اینکه حجم دیتاست از مقدار رم ما بیشتر باشه یک چیز معمول هست. مدیت یک فلگ مخصوص داره که در صورتی که فعال باشه میاد و از حافظه شما (SSD - HDD) استفاده میکنه تا هر مقدار بیشتر از رم بود رو در حافظه ذخیره کنه اینطوری دیگه مشکل کارکرد با دیتاست های بزرگ رو ندارید.
برای فعال سازیش نیازمند این هستیم که MODIN_OUT_OF_CORE رو TRUE کنیم. در لینوکس با دستور زیر امکان پذیر هستش.
export MODIN_OUT_OF_CORE=true
```python
جمع بندی:
اینجا درباره افزایش سرعت پانداس با استفاده از مدین صحبت کردیم که تنها با تغییر کوچیکی در بخش import حاصل شد و حداقل در چندین بخش ما افزایش سرعت رو تجربه کردیم. در صورتی که دوست دارید بیشتر درباره پانداس و استفاده های اون صحبت کنم توی نظرات اعلام کنید.
\*\* این مطلب ترجمه شده همراه با تغییرات از kdnuggets به ادرس [https://www.kdnuggets.com/2019/11/speed-up-pandas-4x.html](https://www.kdnuggets.com/2019/11/speed-up-pandas-4x.html) میباشد.